

👋 Hola, soy Omar y bienvenido al 🎉newsletter de IA y la vida. Cada semana abordaremos humildemente las preguntas de los lectores sobre el producto, el crecimiento, el trabajo con humanos y cualquier otra cosa que te estrese en la oficina. Sígueme en Twitter 🙌.
Si te gusta te agradecería que lo compartas! Esa es nuestra gasolina 🦾.
Para facilitar la comprensión de cada tema, especialmente al momento de programar, te invito a revisar nuestro diccionario inglés-español para programación (link).
Este newsletter es traído a ti por Roam Research...
Roam te permite fácilmente asociar ideas gracias a su asociación bidireccional, algo que no he encontrado en otra aplicación de notas. Llevo usándolo algunos días y tengo que admitir que me quedaré con mi suscripción.
En el texto anterior creamos nuestro primer objeto instanciado de una subclase de tipo torch.utils.data.Dataset. En esta oportunidad, visualizaremos nuestro dataset y aprenderemos a cómo transformar los datos.
Visualizando nuestro dataset
Con el paquete matplotlib.pyplot es suficiente para visualizar el estado de nuestras imágenes. Este paquete contiene funciones que permiten interactuar con nuestras figuras como si fuera Matlab, o incluso R (ver documentación de matplotlib). Cada función de pyplot nos permite agregar algo a nuestra figura: título, labels, cuadriculado, un reacomodo de las figuras, etc. Para más se pueden consultar los tutoriales oficiales.
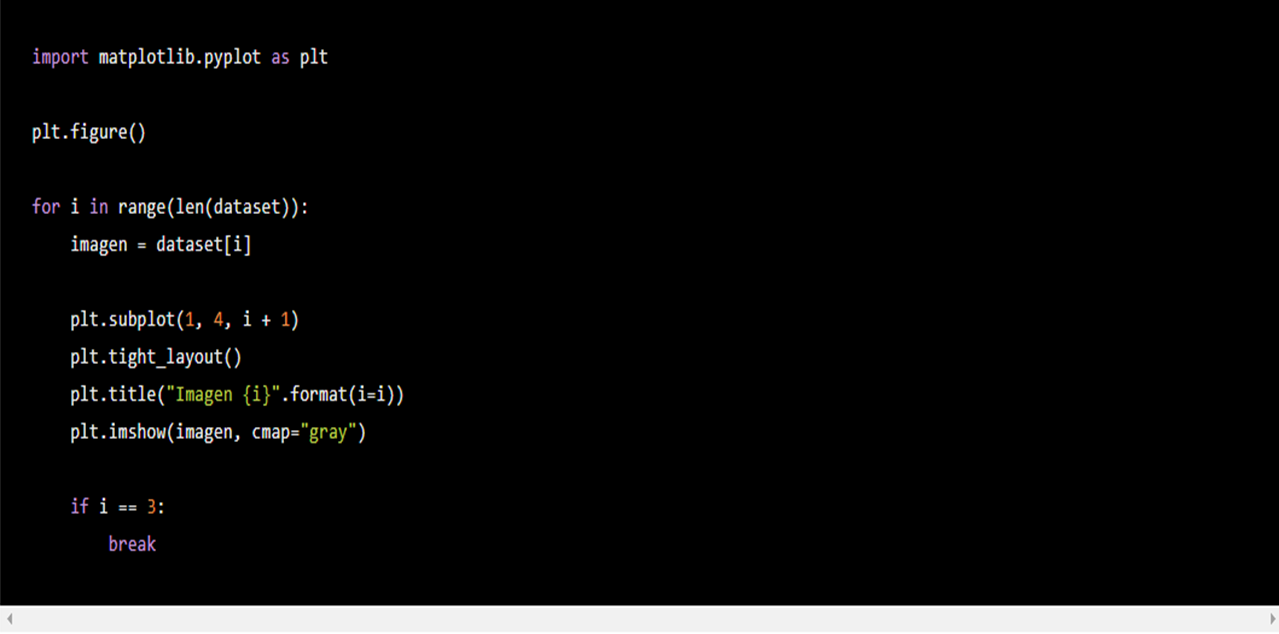
Primero usemos el siguiente código sobre nuestro dataset instanciado de nuestra subclase MNISTDataset:
que nos retorna:

El código importa el paquete matplotlib.pyplot con el sobrenombre plt para crear una serie de cuatro imágenes en el eje horizontal. plt.figure() indica que vamos a crear una nueva figura en las siguientes líneas de código. Con un for indicamos que vamos a ir por todas las fotos de nuestro dataset: len(dataset) nos retorna el número de imágenes en nuestro dataset mientras que range nos crea un rango de 0 al valor ingresado como su argumento, en este caso el número de imágenes. Por lo tanto, dataset[i] nos retorna la imagen número i de dataset. Al final, incluimos la condición if i == 3 para solo mostrar, con plt.show(), las imágenes con índice 0,1,2 y 3 y terminamos el loop con break.
plt.subplot(1, 4, i + 1) indica en el primer argumento el número de filas que tendrá nuestra figura; en el segundo el número de columnas; y en el tercero nos dice la posición que toma la imagen i en nuestra subplot. En este caso queremos que la posición cambie según el índice, i, en el que vamos, por ejemplo, queremos que la primera imagen i = 0, aparezca en la posición número i + 1 = 1 y así sucesivamente.
plt.tight_layout() permite que nuestras imágenes quepan adecuadamente en nuestra figura, podemos no utilizar este comando pero hace que nuestra figura se vea mejor. Finalmente, plt.imshow(imagen, cmap='gray') imprime la imagen. cmap="gray" indica que queremos que el "mapa de color" sea en escala de grises. Listo, podemos observar nuestras imágenes.
Transformando los datos
PyTorch nos permite agregar transformaciones a nuestras imágenes, esto es útil por ejemplo en los casos en que nuestras imágenes tengan diferentes tamaños (para poderlas pasar por el grafo de nuestro modelo debemos tenerlas con el mismo tamaño), necesitemos aumentar el tamaño de nuestro dataset, o simplemente queramos modificarlas.
Para esto recurrimos al paquete torchvision.transforms.

En este paquete encontramos herramientas para crear transformaciones en forma de clases con métodos mágicos __call__ que les permite ser llamadas como funciones, por ejemplo, torchvision.transforms.CenterCrop para cortar una imagen por el centro, o torchvision.transforms.ToTensor para convertir una imagen en formato PIL o numpy a tensores.
Más aún, encontramos una herramienta para encadenar transformaciones y aplicarlas de golpe a una imagen.
torchvision.transforms.Compose permite poner en orden las transformaciones que se aplicarán. El ejemplo de la documentación es:
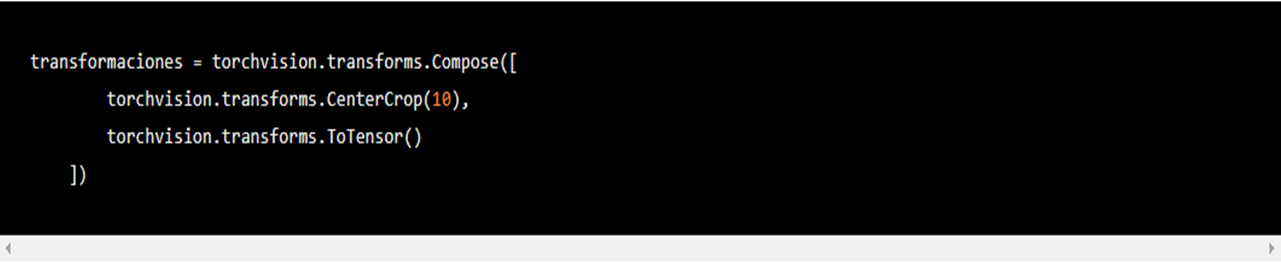
En ese sentido, estamos primero cortando por el centro nuestras imágenes y después convirtiéndolas en tensores. Las transformaciones en torchvision.transforms se aplican solo en tensores o PIL Images, no numpy, no pandas. En la columna derecha de la documentación de torchvision.transforms encuentras las secciones "Transforms on PIL Image" y "Transforms on Torch.*Tensor". Si nuestros datos no vienen originalmente en estos formatos, como nuestros MNIST originalmente en numpy, podemos convertirlos fácilmente a PIL o tensores. La mayoría de las transformaciones son aplicables solo para PIL Images por lo que preferimos convertir nuestros datos a este formato agregando transforms.ToPILImage() al inicio de nuestro torchvision.transforms.Compose:
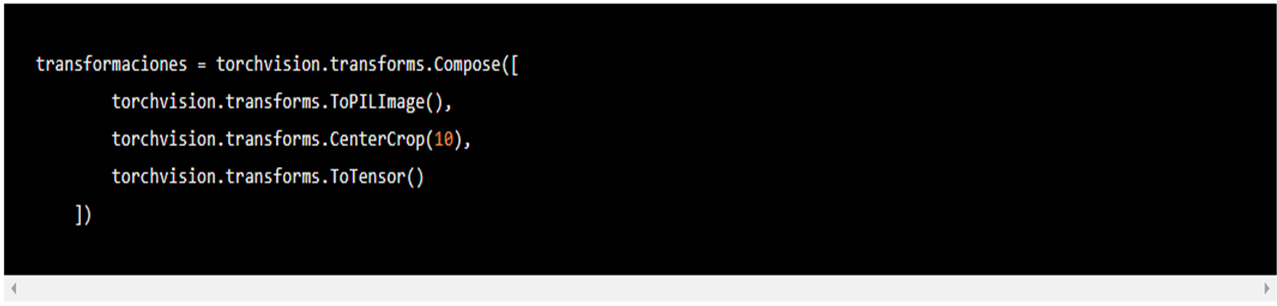
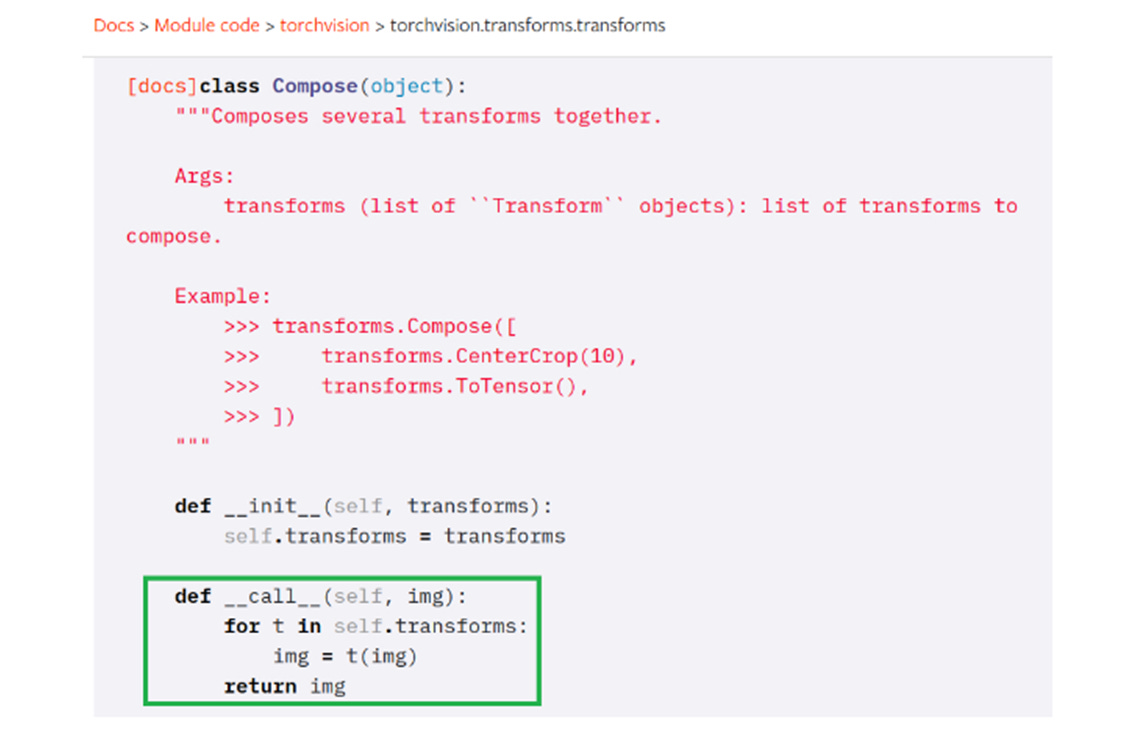
Ahora algo de Python. Si dentro de la documentación ingresamos al código fuente de torchvision.transforms.Compose, veremos que es una clase con el método mágico __call__(self, img) (ver fragmento de código en la siguiente imagen). Esto quiere decir que podemos aplicar la clase como si aplicáramos una función con el argumento img.
Podemos correr las transformaciones sobre una de nuestras imágenes en nuestro objeto dataset instanciado de MNISTDataset: imagen_trans = transformaciones(dataset[0]) y nos retornará nuestra primera imagen pero con las transformaciones aplicadas. Originalmente, la imagen estaba en formato numpy, ahora es un tensor.
Para visualizar nuestras nuevas imágenes utilicemos el mismo código previo pero adecuado a la visualización de un tensor.
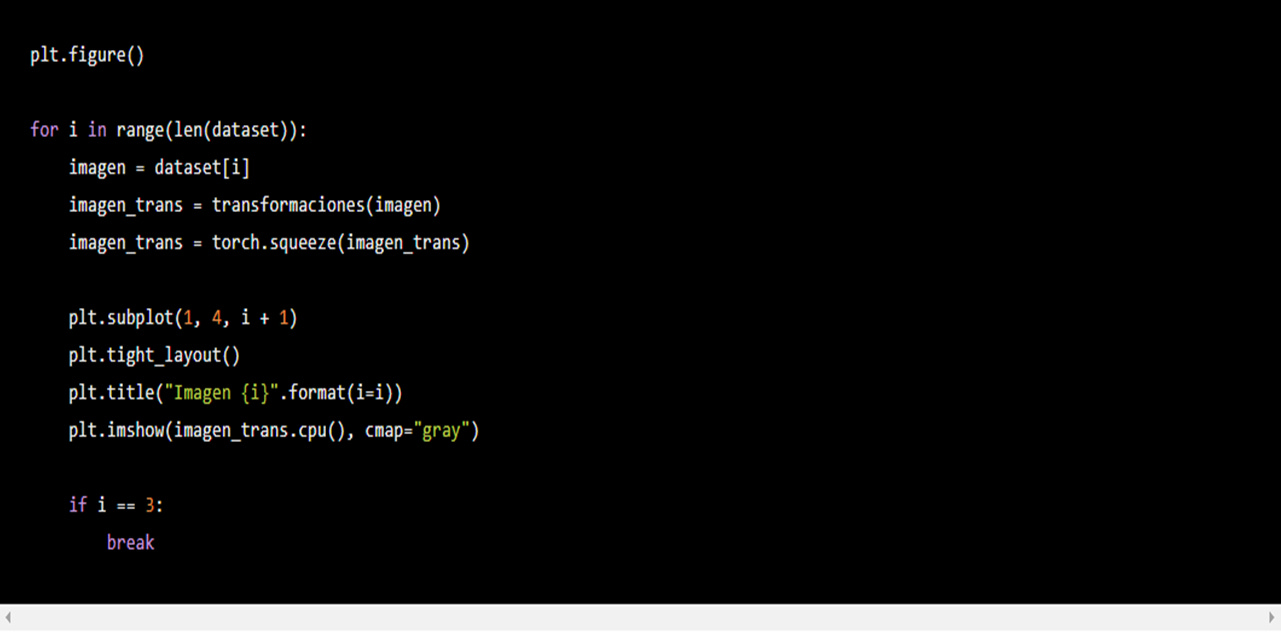
¿Qué es nuevo? Con imagen_trans = transformaciones(imagen) transformamos nuestra imagen extraída de dataset. al poner imagen_trans.shape notamos que la forma de la imagen es torch.Size([1, 14, 14]).plt.imshow no nos permite visualizar imágenes con este formato (corre el código sin esa línea y el error que verás será muy claro), tenemos que eliminar el 1 de la primera dimensión. Para esto corremos imagen_trans = torch.squeeze(imagen_trans) que busca la dimensión donde haya un 1 y la elimina dejándonos el tensor con forma torch.Size([14, 14]). Para más sobre cómo manipular tensores puedes leer "Manipulación de tensores en PyTorch. ¡El primer paso para el deep learning!". Lo último diferente es plt.imshow(imagen_trans.cpu(), cmap="gray"); estamos diciendo que imagen_trans puede ser corrido por un CPU, requerimiento de plt.imshow. El resultado muestra que las transformaciones elegidas no eran las ideales para el caso particular de nuestras imágenes:
Recortar a la mitad el tamaño de nuestras imágenes con torchvision.transforms.CenterCrop(14) no fue lo más inteligente (¡que conste que estábamos siguiendo el ejemplo de la documentación!). Usemos una transformación más adecuada, hagamos que nuestras imágenes se volteen verticalmente.
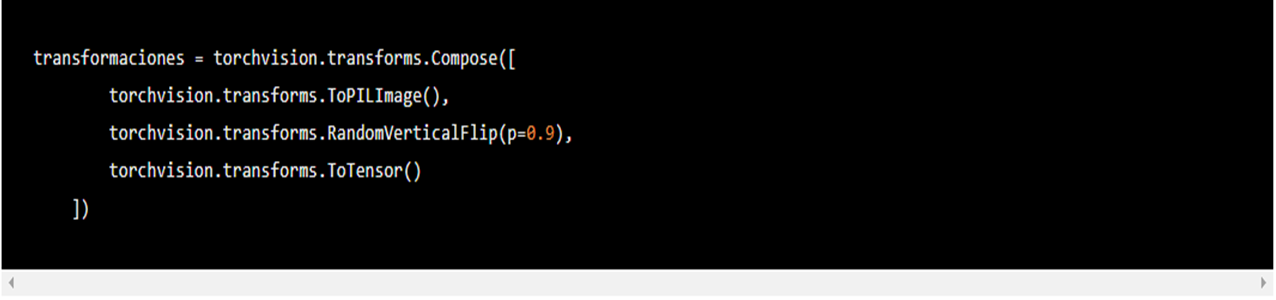
Con torchvision.transforms.RandomVerticalFlip(p=0.9) indicamos que con probabilidad de 0.9 vamos a voltear imágenes de nuestro dataset. En este caso nuestras primeras cuatro imágenes todas fueron volteadas.
Es conveniente que las transformaciones se hagan imagen por imagen pero dentro de nuestra subclase de torch.utils.data.Dataset, MNISTDataset. Así evitamos ocupar más espacio en la memoria al tener al mismo tiempo el conjunto de datos sin transformaciones y el conjunto con transformaciones; ante una base de datos con miles de imágenes apreciaremos esto. Alteremos nuestro MNISTDataset para que el método __getitem__ haga las transformaciones por nosotros cada vez que llamemos una imagen de nuestros dataset. Además, incluyamos nuestras etiquetas, y_train, para cada una de las imágenes, que la imagen con un 5 dibujado vaya acompañada de un 5 en número entero como etiqueta. Para esto haremos que nuestra MNISTDataset nos retorne un diccionario de Python con dos cosas, la imagen (como lo habíamos estado trabajando) y su etiqueta. Así queda nuestra subclase:
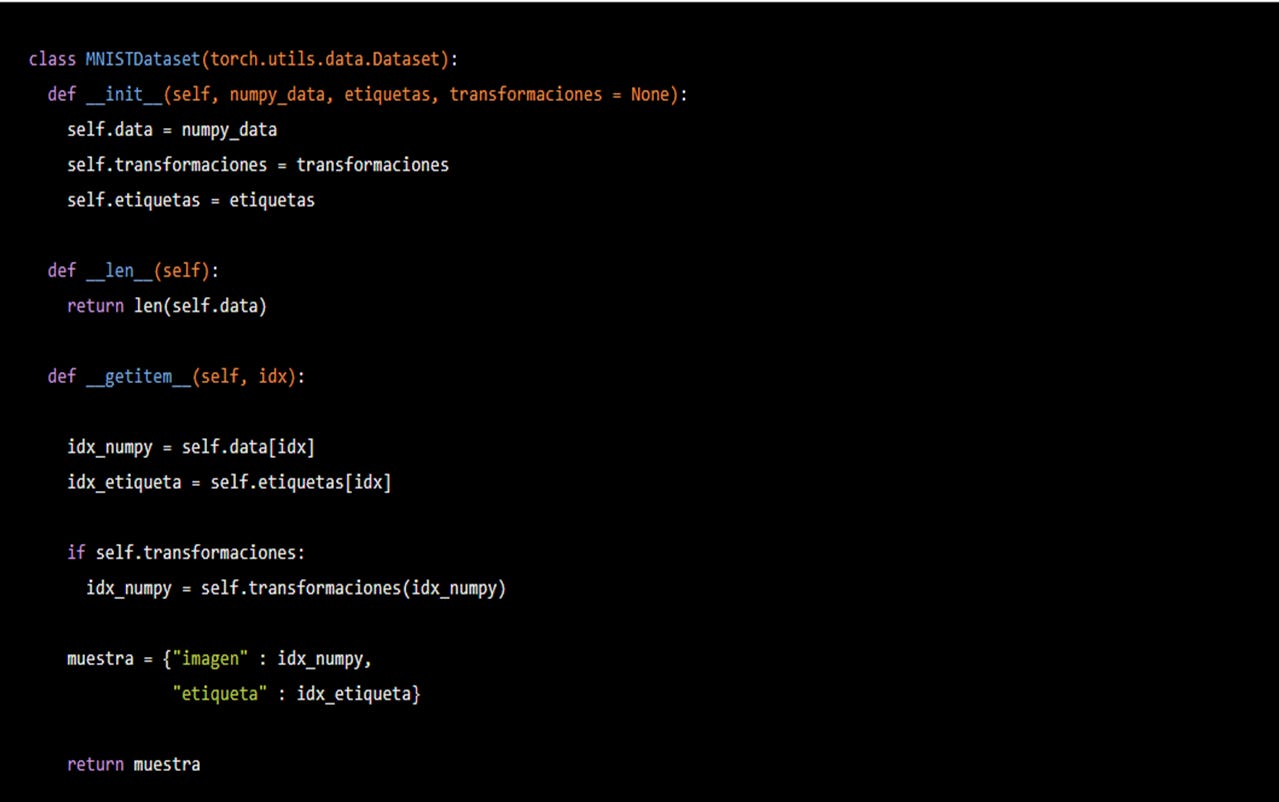
¿Qué es nuevo? Primero, en el método constructor estamos incluyendo dos argumentos formales: las etiquetas y las transformaciones. Segundo, el método __getitem__(self, idx) ahora también guarda la etiqueta correspondiente a la imagen númeroidxenidx_etiqueta. Tercero, si un objeto de clase torchvision.transforms.Composefue ingresado como argumento, se aplica su lista de transformaciones a la imagen númeroidx,en este casoidx_numpy. Por último, creamos un diccionario que contiene dos keys (llaves en español): la primera es "imagen" y contiene a la imagenidx; la segunda es "etiqueta" y contiene la respectiva etiquetaidx.
Listo. Tenemos un dataset que cada que vez que sea convocado leerá una imagen, la transformará y nos la regresará con su etiqueta.
DataLoader
El último paso para tener listos nuestros datos para el entrenamiento es convertir nuestro dataset, instancia de la subclase MNISTDataset, en un objeto de tipo torch.utils.data.DataLoader. Con él podemos, entre otras cosas, manejar la cantidad de imágenes que queremos que tenga cada batch (lote en español) y podemos hacer que nuestras imágenes sean shuffled (barajeadas en español) cada vez que comencemos una nueva ronda de entrenamiento (epoch es el nombre oficial, lo veremos en otro texto).
A él debemos ingresar un objeto instanciado de una subclase de la clasetorch.utils.data.Dataset;perfecto para nuestrodataset de claseMNISTDataset.

Estamos indicando que queremos que cada batch tenga cuatro imágenes; y que cada vez que iniciemos una nueva ronda de entrenamiento, el Dataset sea barajeado de forma que nuestro DataLoader nos regrese diferentes imágenes en cada batch. En otro texto veremos cómo nos ayuda esto para el entrenamiento.
Si bien un objeto torch.utils.data.DataLoader no es un iterador, podemos utilizar next(iter(dataloader)) para acceder a los batches de nuestroDataset,más explícitamente, cada vez que corramosnext(iter(dataloader))accederemos a un batch diferente.

Aquí está la magia de torch.utils.data.DataLoader. batch es un diccionario, tal como lo que imprime nuestro dataset, que acumuló ocho imágenes y ocho etiquetas. En otras palabras, dataset[i] nos retorna un diccionario con una imagen, key imagen, y con una etiqueta, key etiqueta, dataloader nos regresa un diccionaro con las mismas keys pero cada una ocho elementos correspondientes al tamaño definido del batch.
En siguientes textos veremos por qué es tan útil tener nuestros datos en este formato porque comenzaremos con la creación de nuestros modelos.
Buena Suerte! Para cualquier comentario, sígueme en Twitter.
Un agradecimiento especial a Mar y Yadnielis por su ayuda en la edición.